SQL 기본 2(DML)
DML (Data Manipulation Language)
1. INSERT
- 테이블에 데이터 삽입
Systax
1) 몇개의 컬럼만 지정해서 INSERT
INSERT INTO 테이블명 (컬렴1, 컬럼2) VALUES (데이터1, 데이터2);* 컬럼의 순서는 테이블 컬럼 순서와 매치할 필요 없으며, 정의하지 않은 칼럼에는 NULL값 삽입
2. 전체 컬럼을 대상으로 INSERT
INSERT INTO 테이블명 VALUES (전체 컬럼에 대한 데이터 삽입);* 칼럼의 순서대로 빠짐없이 데이터가 입력되어야 함
2. UPDATE
- 데이터 값 수정
Systax
UPDATE 테이블명 SET 수정되기전 칼럼명 = 수정될 새로운 값;
3. DELETE
- 데이터 삭제
Syntax
DELETE [FROM] 테이블명;* WHERE 절을 사용하지 않으면 테이블 전체 데이터가 삭제된다.
4. SELECT
- 조회
Syntax
SELECT [DISTINCT] *
FROM 테이블명
[WHERE 조건]
4-1 ALIAS 부여하기
- 조회된 결과에 별명(ALIAS) 부여
- 칼럼명 바로 뒤에 선언
- AS, as 키워드 사용 가능
- " " 을 사용하면 공백, 특수문자, 대문자 사용가능
5. 산술 연산자와 합성 연산자
1) 산술 연산자
- NUMBER, DATE 자료형에 대해 적용
- 일반적으로 수학에서의 4칙 연산과 동일

2) 합성(CONCATENATION) 연산자
- 문자와 문자를 연결
- ( || )
TCL
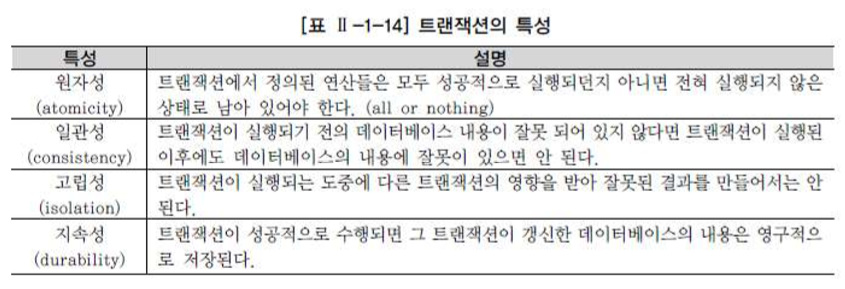
1. 트래잭션(TRANSACTION) 개요
- 트랜잭션은 데이터베이스의 논리적 연산단위
- 트랜잭션이란 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조직을 가리킴
- 트랜잭션에는 하나 이상의 SQL문장이 포함
- 트랜잭션은 분할할 수 없는 최소의 단위
* 전부 적용하거나 전부 취소 => TRANSACTION = ALL OR NOTHING
- 데이터베이스에 반영 시키는 것을 COMMIT
- 트랜잭션 시작 이전의 상태로 되돌리는 것을 ROLLBACK
- 저장점 SAVEPOINT
- 3가지 명령어로 트랜잭션을 컨트롤하는 TCL(TRANSACTION CONTROL LANGUAGE)
2. COMMIT
1) AUTO COMMIT
- SQL Server의 기본 방식
- 성공적으로 수행되면 자동 COMMIT
- 오류가 발생하면 자동 ROLLBACK
2) 암시적 TRANSACTION
- ORACLE 기본 방식
- 트랜잭션의 시작은 DBMS가 처리, 끝은 사용자가 명시적으로 COMMIT 또는 ROLLBACK으로 처리
- 인스턴스 단위 OR 세션 단위로 설정가능
- 인스턴스 단위로 설정하려면 서버 속성 창의 연결화면에서 기본 연결 옵션 중 암시적 트랜잭션에 체크
- 세션 단위로 설정하기 위해서는 세션 옵션 중 SET IMPLICIT TRANSACTION ON을 사용
3) 명시적 TRANSACTION
- 트랜잭션의 시작과 끝을 사용자가 모두 명시적으로 지정
- BEGIN TRANSACTION 으로 트랜잭션 시작, COMMIT 또는 ROLLBACK으로 트랜잭션 종료
- ROLLBACK 구문을 만나면 최초의 BEGIN TRANSACTION 시점까지 모두 ROLLBACK이 수행
3. ROLLBACK
- 데이터 변경 사항이 취소되어 데이터의 이전 상태로 복구
- 관련된 행에 대한 잠금(LOCKING)이 풀리고 다른 사용자들이 데이터 변경 가능
=> COMMIT과 ROLLBACK을 사용함으로써 다음과 같은 효과
1] 데이터의 무결성 보장
2] 영구적인 변경을 하기 전에 데이터의 변경 사항 확인 가능
3] 논리적으로 연관된 작업을 그룹핑하여 처리 가능
4. SAVEPOINT
- 저장점을 정의하면 ROLLBACK을 할 때 트랜잭션에 포함된 전체 작업을 롤백하는 것이 아니라
현 시점에서 SAVEPOINT까지 트랜잭션의 일부만 롤백할 수 있다.
- 동일 이름으로 저장점을 정의했을 때는 나중에 정의한 저장점이 유효
Systax
SAVEPOINT SVPT1;
ROLLBACK TO SVPT1;
WHERE
1. WHERE 조건절 개요
2. 연산자의 종류
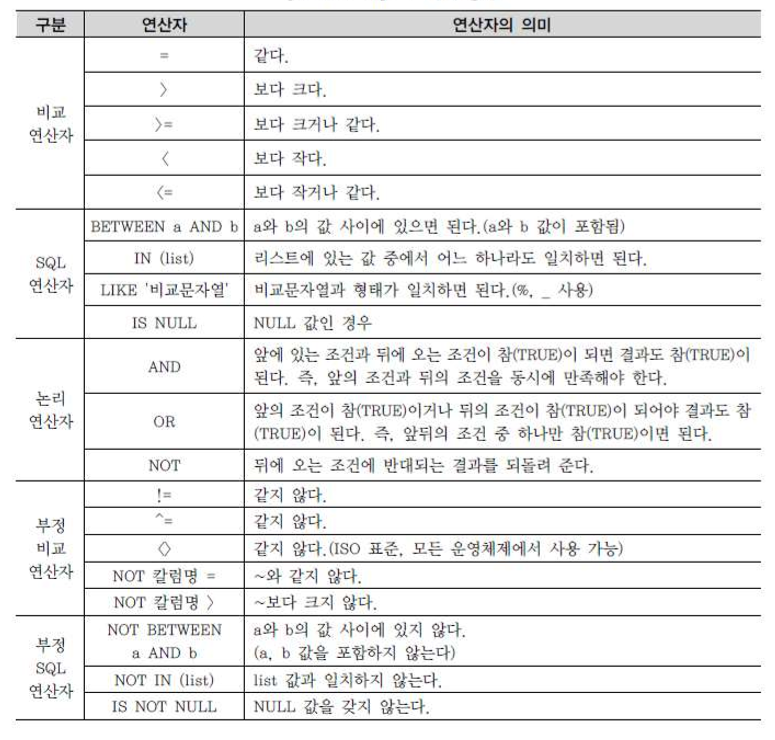

3. 비교 연산자



5. ROWNUM, TOP 사용
5-1 ROWNUM
- ROWNUM은 컬럼과 비슷한 성격의 Pseudo COLUMN으로써 SQL 처리 결과 집합의 각 행에 대해
임시로 부여되는 일련번호
- 테이블이나 집합에서 원하는 만큼의 행만 가져오고 싶을 때 WHERE 절에서 행의 개수를 제한하는 목적으로 사용
5-2 TOP
Syntax
TOP (Expression) [PERCENT] [WITH TIES]* Expression : 반환할 행의 수를 지정하는 숫자
PERCENT : 쿼리 결과 집합에서 처음 Expression%의 행만 반환됨을 나타냄
WITH TIES : ORDER BY 절이 지정된 경우에만 사용할 수 잇으며, TOP N (PERCENT)의 마지막 행과
같은 값이 있는 경우 추가 행이 출력되도록 지정할 수 있다.
함수 (FUNCTION)
1. 내장 함수(BUILT - IN FUNCTION) 개요
- 종류
1) 단일행 함수 (Single - Row Function) : 함수 입력값이 한개
2) 다중행 함수 (Multi - Row Function) : 함수 입력값이 여러개
2-1) 집계함수 (Aggreagate Function)
2-2) 그룹함수 (Group Function)
2-3) 윈도우 함수 (Window Function)
단일행 함수의 종류
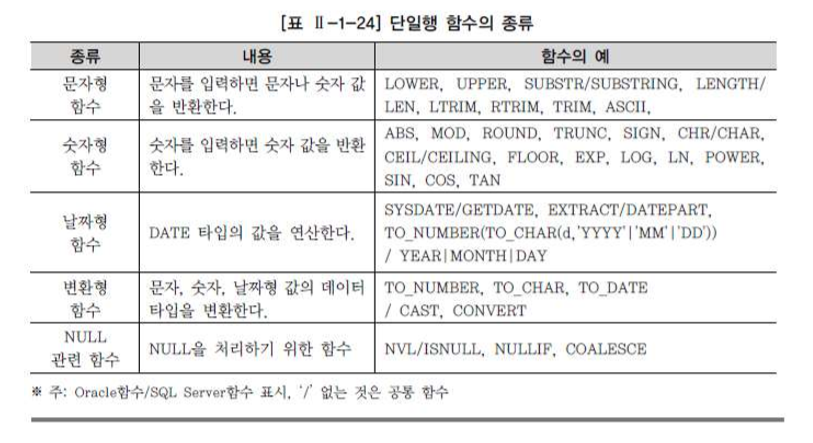
단일행 함수의 특징
- SELECT, WHERE, ORDER BY절에 사용 가능
- 각 행(ROW)들에 대해 개별적으로 작용하여 데이터 값들을 조작하고, 각각의 행에 대한 조작 결과를 리턴
- 여러 인자(Argument) 를 입력해도 단 하나의 결과만 리턴한다.
- 함수의 인자(Argument)로 상수, 변수, 표현식이 사용 가능하고, 하나의 인수를 가지는 경우도 있지만
여러 개의 인수를 가질 수도 있다.
- 특별한 경우가 아니면 함수의 인자(Arguments)로 함수를 사용하는 함수의 중첩이 가능
2. 문자형 함수
- 문자형 함수는 문자 데이터를 매개 변수로 받아들여서 문자나 숫자 값의 결과를 돌려주는 함수
몇몇 문자형 함수의 경우는 결과를 숫자로 리턴하는 함수도 있다.


3. 숫자형 함수
- 숫자 데이터를 입력받아 처리하고 숫자를 리턴하는 함수


4. 날짜형 함수
- DATE 타입의 값을 연산하는 함수

* ORACLE 에서는 TO_NUMBER(TO_CHAR())의 함수를 사용하기도 함

5. 변환형 함수
- 변환형 함수는 특정 데이터 타이을 다양한 형식으로 출력하고 싶을 경우에 사용되는 함수
변환형 함수는 크게 두 가지 방식이 있다.

암시적 데이터 유형 변환의 경우 성능 저하가 발생할 수 있으며, 자동으로 데이터베이스가 알아서 계산하지 않는 경우가
있어 에러가 발생할 수 있으므로 명시적인 데이터 유형 변환 방법을 사용하는 것이 바람직
명시적 데이터 유형 변환 함수

6. CASE 표현

7. NULL 관련 함수
NULL의 특성
- 정의되지 않은 값으로 0 또는 공백과는 다름
- 공백은 하나의 문자이다.
- 테이블을 생성할 때 NOT NULL 또는 PRIMARY KEY로 정의되지 않은 모든 데이터 유형은 NULL값을 포함할 수 있다.
- NULL값을 포함하는 연산의 경우 결과 값도 NULL이다.
* 모르는 데이터에 숫자를 더하거나 빼도 결과는 마찬가지로 모르는 데이터인 것과 같다.
- 결과값을 NULL이 아닌 다른 값을 얻고자 할 때 NVL / ISNULL 함수를 사용
1) NVL / ISNULL 함수
- NULL값 처리

2. NULL과 공집합
- 데이터를 찾을 수 없는 경우 공집합이 발생하는데, 이 때는 적절한 집계함수를 이용해서
NVL함수 대신 적용한다.
GROUP BY, HAVING 절
1. 집계 함수(Aggregate Function)
여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 다중행 함수 중 집계함수의 특성
- 여러 행들의 그룹이 모여서 단 하나의 결과를 돌려주는 함수
- GROUP BY절은 행들을 소그룹화
- SELECT 절, HAVING 절, ORDER BY 절에 사용 가능

2. GROUP BY 절
- FROM절과 WHERE절 뒤에 위치
- 데이터들을 작은 그룹으로 분류하여 소그룹에 대한 항목별로 통계 정보를 얻을 때 추가로 사용
Systax
SELECT *
FROM 테이블명
WHERE 조건
GROUP BY Expression
HAVING 그룹조건식;
특성
- GROUP BY절을 통해 소그룹별 기준을 정한 후, SELECT 절에 집계 함수 사용
- 집계 함수의 통계 정보는 NULL값을 가진 행을 제외하고 수행
- GROUP BY절에서는 SELECT 절과는 달리 ALIAS명을 사용할 수 없다.
- 집계 함수는 WHERE절에 위치할 수 없다. (WHERE절이 ORDER BY절보다 먼저 수행)
- WHERE절은 전체 데이터를 GROUP BY절로 나누기 전에 행들을 미리 제거
- HAVING절은 GROUP BY절의 기준 항목이나 소그룹의 집계 함수를 이용한 조건 표시 가능
- GROUP BY절에 의한 소그룹별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어
조건을 만족하는 내용만 출력
- HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치
HAVING 절
- HAVING 조건절에는 GROUP BY 절에서 정의한 소그룹의 집계 함수를 이용한 조건을 표시할 수 있으므로
HAVING 절을 이용해 평균키가 180 센티미터 이상인 정보만 표시
※ 오류출력문 1.

오류 원인 : WHERE 절에는 그룹함수를 사용할 수 없다.
-> WHERE 절은 FROM절에 정의된 집합(주로 테이블)의 개별 행에 WHERE절의 조건이 먼저 적용되고
WHERE절에 맞는 행이 GROUP BY절의 대상이 된다.
그 다음, 결과 집합의 행에 HAVING 조건절이 적용된다.
=> 결과적으로 HAVING절의 조건을 만족하는 내용만 출력된다. ?? 아닌거같은데 WHER절에서 한번거르니까
※ 올바른 QUERY
